在回归问题中,我们的目标是预测连续值的输出,比如价格或概率。然而在分类问题中,我们的目标是从类列表中选择一个类(例如,一幅图片包含一个苹果或一个橘子,而我们的目标就是识别出图中有哪些水果)。
本文将使用经典的汽车MPG数据集,并建立了一个模型来预测70年代末、80年代初汽车的燃油效率。为了做到这一点,我们将为模型提供当时很多汽车的属性,包括:气缸、排量、马力和重量。
我们依然使用tf.keras API来完成本例。
首先,导入本文将要使用的库:
import pathlib
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)2.0.0-beta0一、处理数据集
该数据集可以从UCI机器学习仓库中获得。
1. 获取数据
首先,下载数据集。
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_pathDownloading data from http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data
32768/30286 [================================] - 0s 6us/step
'/root/.keras/datasets/auto-mpg.data'使用Pandas读取数据文件:
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(dataset_path, names=column_names,
na_values="?", comment='\t',
sep=' ', skipinitialspace=True)
dataset = raw_dataset.copy()
dataset.tail()| MPG | Cylinders | Displacement | Horsepower | Weight | Acceleration | Model Year | Origin | |
|---|---|---|---|---|---|---|---|---|
| 393 | 27.0 | 4 | 140.0 | 86.0 | 2790.0 | 15.6 | 82 | 1 |
| 394 | 44.0 | 4 | 97.0 | 52.0 | 2130.0 | 24.6 | 82 | 2 |
| 395 | 32.0 | 4 | 135.0 | 84.0 | 2295.0 | 11.6 | 82 | 1 |
| 396 | 28.0 | 4 | 120.0 | 79.0 | 2625.0 | 18.6 | 82 | 1 |
| 397 | 31.0 | 4 | 119.0 | 82.0 | 2720.0 | 19.4 | 82 | 1 |
2. 清理数据
检查数据集中是否包含一些未知数据(空值)。
dataset.isna().sum()MPG 0
Cylinders 0
Displacement 0
Horsepower 6
Weight 0
Acceleration 0
Model Year 0
Origin 0
dtype: int64可以看到,有6行数据的Horsepower列是空值,简单起见,我们直接删除这些行:
dataset = dataset.dropna()Origin列实际上是分类列,而不是数字的,所以我们把它转换成one-hot:
origin = dataset.pop('Origin')
dataset['USA'] = (origin == 1) * 1.0
dataset['Europe'] = (origin == 2) * 1.0
dataset['Japan'] = (origin == 3) * 1.0
dataset.tail()| MPG | Cylinders | Displacement | Horsepower | Weight | Acceleration | Model Year | USA | Europe | Japan | |
|---|---|---|---|---|---|---|---|---|---|---|
| 393 | 27.0 | 4 | 140.0 | 86.0 | 2790.0 | 15.6 | 82 | 1.0 | 0.0 | 0.0 |
| 394 | 44.0 | 4 | 97.0 | 52.0 | 2130.0 | 24.6 | 82 | 0.0 | 1.0 | 0.0 |
| 395 | 32.0 | 4 | 135.0 | 84.0 | 2295.0 | 11.6 | 82 | 1.0 | 0.0 | 0.0 |
| 396 | 28.0 | 4 | 120.0 | 79.0 | 2625.0 | 18.6 | 82 | 1.0 | 0.0 | 0.0 |
| 397 | 31.0 | 4 | 119.0 | 82.0 | 2720.0 | 19.4 | 82 | 1.0 | 0.0 | 0.0 |
3. 将数据集拆分为训练集和测试集
现在,我们将数据集拆分为训练集和测试集。我们将在对模型进行最终评估时使用测试集。
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)4. 检视数据
让我们快速查看一下训练集中几列数据之间的联合分布。
sns.pairplot(train_dataset[['MPG', 'Cylinders', 'Displacement', 'Weight']], diag_kind='kde')<seaborn.axisgrid.PairGrid at 0x7f5f384fa6a0>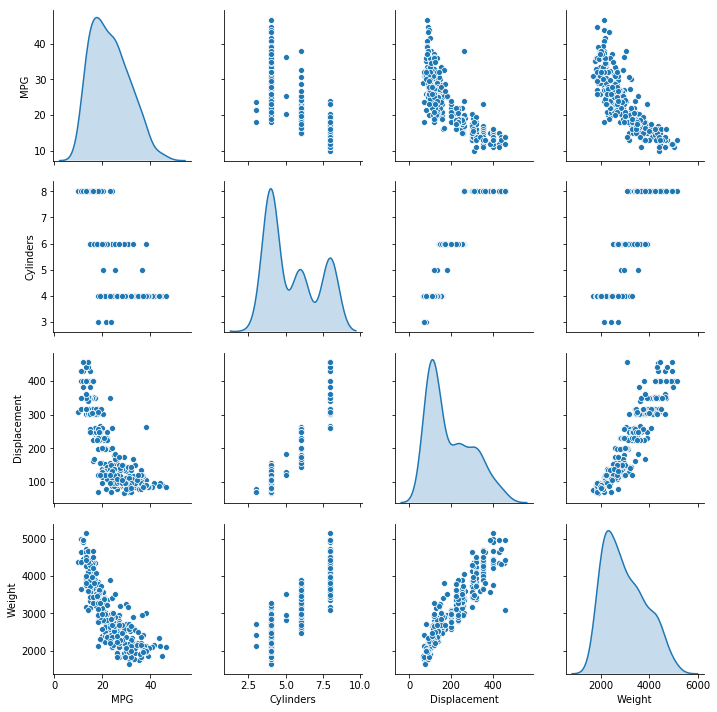
再看看整个数据集的统计结果:
train_stats = train_dataset.describe()
train_stats.pop('MPG')
train_stats = train_stats.transpose()
train_stats| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Cylinders | 314.0 | 5.477707 | 1.699788 | 3.0 | 4.00 | 4.0 | 8.00 | 8.0 |
| Displacement | 314.0 | 195.318471 | 104.331589 | 68.0 | 105.50 | 151.0 | 265.75 | 455.0 |
| Horsepower | 314.0 | 104.869427 | 38.096214 | 46.0 | 76.25 | 94.5 | 128.00 | 225.0 |
| Weight | 314.0 | 2990.251592 | 843.898596 | 1649.0 | 2256.50 | 2822.5 | 3608.00 | 5140.0 |
| Acceleration | 314.0 | 15.559236 | 2.789230 | 8.0 | 13.80 | 15.5 | 17.20 | 24.8 |
| Model Year | 314.0 | 75.898089 | 3.675642 | 70.0 | 73.00 | 76.0 | 79.00 | 82.0 |
| USA | 314.0 | 0.624204 | 0.485101 | 0.0 | 0.00 | 1.0 | 1.00 | 1.0 |
| Europe | 314.0 | 0.178344 | 0.383413 | 0.0 | 0.00 | 0.0 | 0.00 | 1.0 |
| Japan | 314.0 | 0.197452 | 0.398712 | 0.0 | 0.00 | 0.0 | 0.00 | 1.0 |
5. 从数据中取出目标值
将目标值从数据中分离出来,这个目标值是您将通过训练的模型来预测的值。
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')6. 正则化数据
再次查看上面的train_stats表,你会注意到每个特征值的范围都不同。
把具有不同范围值的特征正则化(归一化)是一个很好的实践。虽然模型在不进行特征归一化的情况下也可以收敛,但这会增加训练的难度,并使生成的模型依赖于输入数据中的单位选择。
注意:虽然我们有意只从训练数据集生成这些统计数据,但是这些统计数据也将用于
正则化测试数据集。这样做是为了将测试数据集也投射到模型所训练的相同分布中。
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)我们将使用这些正则化的数据来训练模型。
警告:这里用于正则化输入的统计数据(
平均值和标准偏差)需要应用于任何其他提供给模型的数据,以及我们前面所做的one-hot编码,这包括在生产中使用模型时的测试集和实时数据。
二、 处理模型
1. 构建模型
让我们构建我们的模型。在这里,我们将使用一个Sequential模型,其中包含两个全连接的隐藏层和一个返回单个连续值的输出层。模型构建步骤封装在函数build_model中,因为稍后我们将用该函数创建另外一个模型。
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = keras.optimizers.RMSprop(0.01)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()2. 检视模型
使用模型的summary函数打印模型的简单描述:
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 64) 640
_________________________________________________________________
dense_1 (Dense) (None, 64) 4160
_________________________________________________________________
dense_2 (Dense) (None, 1) 65
=================================================================
Total params: 4,865
Trainable params: 4,865
Non-trainable params: 0
_________________________________________________________________现在试试这个模型,从训练数据集中取出10个样本,调用模型的predict函数进行预测。
example_batch = normed_train_data[:10]
example_result = model.predict(example_batch)
example_resultarray([[-0.00430702],
[-0.153585 ],
[-0.2786718 ],
[-0.41118544],
[-0.33164966],
[ 0.11375937],
[-0.37117037],
[-0.2712645 ],
[ 0.04279822],
[-0.19775198]], dtype=float32)看起来我们的模型可以正常工作,它可以产生我们预期的形状及类型的预测结果。
3. 训练模型
对模型进行1000次迭代训练,并把训练和验证准确率保存在history对象中。
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print('')
print('.', end='')
EPOCHS = 1000
history = model.fit(
normed_train_data, train_labels,
epochs = EPOCHS, validation_split=0.2, verbose=0,
callbacks=[PrintDot()]
)....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................接下来,我们可以将模型的训练过程进行可视化,我们可以使用history对象中存储的状态。
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail()| loss | mae | mse | val_loss | val_mae | val_mse | epoch | |
|---|---|---|---|---|---|---|---|
| 995 | 1.429395 | 0.805808 | 1.429395 | 14.781130 | 3.153975 | 14.781130 | 995 |
| 996 | 2.564816 | 1.154352 | 2.564816 | 10.677358 | 2.599523 | 10.677358 | 996 |
| 997 | 1.406840 | 0.782063 | 1.406840 | 10.480282 | 2.470785 | 10.480282 | 997 |
| 998 | 1.724082 | 0.887233 | 1.724082 | 9.411325 | 2.464231 | 9.411325 | 998 |
| 999 | 1.458340 | 0.782995 | 1.458340 | 11.574752 | 2.700156 | 11.574753 | 999 |
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Abs Error [MPG]')
plt.plot(hist['epoch'], hist['mae'], label='Train Error')
plt.plot(hist['epoch'], hist['val_mae'], label='Val Error')
plt.ylim([0, 5])
plt.legend()
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Square Error [$MPG^2$]')
plt.plot(hist['epoch'], hist['mse'], label='Train Error')
plt.plot(hist['epoch'], hist['val_mse'], label='Val Error')
plt.ylim([0, 20])
plt.legend()
plt.show()
plot_history(history)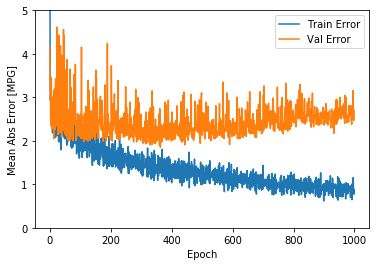
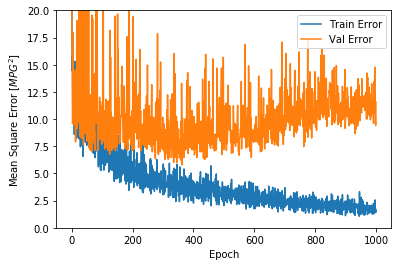
这两张图显示,在大约100次迭代之后,验证错误几乎没有改善,甚至变差。让我们更新model.fit,当验证分数没有提高时自动停止训练。我们将使用一个EarlyStopping回调函数来检查每次迭代,如果在一定迭代次数后一直没有提高准确率,则自动停止训练。
model = build_model()
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(normed_train_data, train_labels, epochs=EPOCHS, validation_split=0.2, verbose=0, callbacks=[early_stop, PrintDot()])
plot_history(history).........................
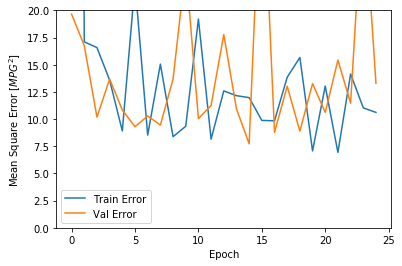
从图中可以看出,在验证集上,平均误差通常在正负2MPG左右。
我们在训练模型时没有使用测试集,现在让我们看看把模型应用在测试集上的效果将如何。这个结果可以告诉我们,当我们在现实世界中使用这个模型时,模型的预测结果是好还是坏。
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=0)
print('Testing set Mean Abs Error: {:5.2f} MPG'.format(mae))Testing set Mean Abs Error: 2.37 MPG4. 进行预测
最后,我们使用测试集中的数据来预测MPG值:
test_predictions = model.predict(normed_test_data).flatten()
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
plt.axis('equal')
plt.axis('square')
plt.xlim([0, plt.xlim()[1]])
plt.ylim([0, plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])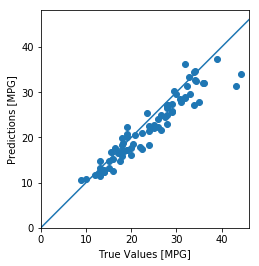
看起来我们的模型预测得相当好。我们来看一下误差分布。
error = test_predictions - test_labels
plt.hist(error, bins=25)
plt.xlabel('Prediction Error [MPG]')
_ = plt.ylabel('Count')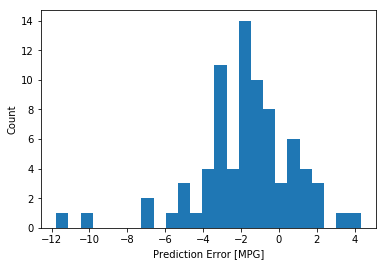
它不是高斯分布的,但我们可以预料到这样的结果是因为样本的数量太小。
三、小结
本文介绍了一些处理回归问题的技术:
均方误差(MSE)是回归问题中常用的损失函数(与分类问题中使用的损失函数不同)。- 类似地,用于回归的评估指标也与分类不同。一个常见的回归度量是
平均绝对误差(MAE)。 - 当数值型输入特征具有不同范围值时,应该将特征缩放到相同的范围,称为
正则化(或归一化)。 - 如果没有足够的训练数据,一种解决的技术是选择具有很少
隐藏层的小型网络来避免过拟合。 - 提前停止训练(
Early Stopping)是一种有效防止过拟合的技术。
本文完整代码请参考这里。



